
DevOps Practices for Azure Infrastructure - Continuous Delivery & Continuous Deployment
In my previous post, I started the journey of implementing DevOps practices for infrastructure. I've proposed implementation for Continuous Integration practice, which covers the Create and Verify stages of the DevOps pipeline.

But Continuous Integration is just the first of several practices which should be implemented for a complete pipeline:
- Continuous Planning
- Continuous Integration
- Continuous Delivery
- Continuous Deployment
- Continuous Testing
- Continuous Operations
- Continuous Monitoring
In this post, I want to focus on Continuous Delivery and Continuous Deployment practices which are there to pick up where Continuous Integration has finished and continue through the Package and Release stages of the pipeline.
Continuous Delivery vs. Continuous Deployment
Quite often, when I'm discussing Software Development Life Cycle with teams, there is confusion around Continuous Delivery and Continuous Deployment. Teams will often say that they are doing CI/CD and when I ask about the CD part the terms Continuous Delivery and Continuous Deployment are being used interchangeably. A lot of marketing "What is DevOps" articles also don't help by confusing the terms. So what is the difference?
In short, Continuous Delivery is about making artifacts ready for deployment and Continuous Deployment is about actually deploying them. That seems to be quite a clear separation, so why the confusion? Because in the real world, they often blend. In an ideal scenario, when the Continuous Integration workflow is finished, the deployment workflow can kick off automatically and get the changes to the production. In such a scenario, the Continuous Delivery may not be there, and if it is there it will be considered an implicit part of Continuous Deployment. This is where the terms are often misused - the separation is not clear. Continuous Delivery exists in explicit form only when there is some kind of handover or different step between "packaging" and "deployment".
Why am I discussing this here? Because when it comes to infrastructure, especially for solutions of considerable size, there often is a need for separated Continuous Delivery and Continuous Deployment. Where does this need come from? From different responsibilities. For large solutions, there is infrastructure responsible for the overall environment and infrastructure tied to specific applications. That means multiple teams are owning different parts of the infrastructure and working on it independently. But from a governance and security perspective, there is often a desire to treat the entire infrastructure as one. Properly implemented Continuous Delivery and Continuous Deployment can solve this conflict, but before I move to discuss the practices I need to extend the context by discussing the repositories structure for such solutions.
Structuring Repositories
How repositories of your solutions are structured has an impact on the implementation of your DevOps practices. Very often projects start small with a monorepo structure.
There is nothing wrong with monorepo structure. It can be the only structure you will ever need. The main benefit of monorepo is that it's simple. All your code lives in one place, you can iterate fast, it's easy to govern and you can implement just a single set of DevOps practices. But there is a point at which those advantages are becoming limitations. This point comes when the solutions grow to consist of multiple applications owned by different teams. Sooner or later those teams start to ask for some level of independence. They want to have a little bit different governance rules (which better suit their culture) and they don't want to be blocked by work being done by other teams. Sometimes just the size of monorepo becomes a productivity issue. This is where the decoupling of the monorepo starts. Usually, the first step is that new applications are being created in their own repositories. Later, the existing ones are moved out from the monorepo. The outcome is multiple, independent repositories.

But, this structure has some problems of its own. There is no longer a single source of truth that would represent the entire solution. Establishing governance rules which are required for the entire solution is harder. There are multiple sources of deployments which means access to the environment from multiple places, which means increased security risk. There is a need for balance between those aspects and teams needs in areas of flexibility and productivity. A good option for such a balance is having applications repositories and a dedicated environment repository.

The environment repository is the single source of truth. It's also the place to apply required governance rules and the only source of deployments. It can also hold the shared infrastructure. The applications repositories are owned by the applications teams and contain the source code for the application as well as the infrastructure code tied to it. This is the structure we will focus on because this is the structure that requires Continuous Delivery and Continuous Deployment. The applications teams should implement Continuous Delivery for packaging the infrastructure to be used by the environment repository, while the team responsible for the environment repository should implement Continuous Deployment. Let's start with Continuous Delivery.
Continuous Delivery for Applications Infrastructure
The first idea for Continuous Delivery implementation can be simply copying the infrastructure code to the environment repository. The allure of this approach is that the environment repository will contain the complete code of the infrastructure removing any kind of context switching. The problem is that now the same artifacts live in two places and the sad truth is that when the same artifacts live in two places sooner or later something is going to get messed up. So, instead of copying the infrastructure code a better approach is to establish links from the environment module to the applications modules.
Options for linking from the environment module to applications modules strongly depend on chosen infrastructure as code tooling. Some tools support a wide variety of sources for the links starting with linking directly to git repositories (so Continuous Delivery can be as simple as creating a tag and updating a reference in the environment module). In rare cases, when there is no support for linking by the tooling, you can always use git submodules.
In the case of Bicep, there is one interesting option - using Azure Container Registry. This option can be attractive for two reasons. One is the possibility to create a private, isolated registry. The other is treating infrastructure the same way we would treat containers (so if you are using containers, both are treated similarly).

The publishing of bicep files is available through the az bicep publish command. We can create a workflow around this command. A good trigger for this workflow may be the creation of a tag. We can even extract the version from the tag name which we will later use to publish the module.
name: Continuous Delivery (Sample Application)
on:
push:
tags:
- "sample-application-v[0-9]+.[0-9]+.[0-9]+"
...
jobs:
publish-infrastructure-to-registry:
runs-on: ubuntu-latest
steps:
- name: Extract application version from tag
run: |
echo "APPLICATION_VERSION=${GITHUB_REF/refs\/tags\/sample-application-v/}" >> $GITHUB_ENV
...
Now all that needs to be done is checking-out the repository, connecting to Azure, and pushing the module.
...
env:
INFRASTRUCTURE_REGISTRY: 'crinfrastructuremodules'
jobs:
publish-infrastructure-to-registry:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
steps:
...
- name: Checkout
uses: actions/checkout@v3
- name: Azure Login
uses: azure/login@v1
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Publish application Bicep to infrastructure registry
run: |
bicep publish \
applications/sample-application/application.bicep \
--target br:${INFRASTRUCTURE_REGISTRY}.azurecr.io/infrastructure/applications/sample-application:${APPLICATION_VERSION}
The linking itself is to be done in the environment infrastructure Bicep file. The module syntax allows the module path to be either a local file or a file in a registry. This is the part that applications teams will be contributing to the environment repository - the module definition.
...
resource sampleApplicationResourceGroupReference 'Microsoft.Resources/resourceGroups@2022-09-01' = {
name: 'rg-devops-practices-sample-application-prod'
location: environmentLocation
}
module sampleApplicationResourceGroupModule 'br:crinfrastructuremodules.azurecr.io/infrastructure/applications/sample-application:1.0.0' = {
name: 'rg-devops-practices-sample-application-rg'
scope: resourceGroup(sampleApplicationResourceGroupReference.name)
}
...
Now the Continuous Deployment practice for the environment can be implemented.
Continuous Deployment for Environment Infrastructure
There are two deployment strategies that you may have heard of in the context of deploying infrastructure: push-based deployment and pull-based deployment.
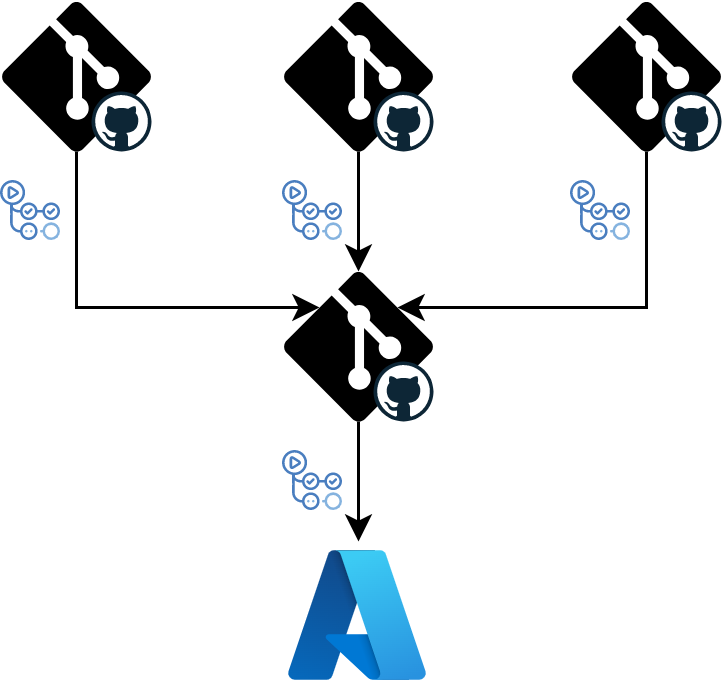
The push-based deployment is what one could call a classic approach to deployment. You implement a workflow that pushes the changes to the environment. That workflow is usually triggered as a result of changes to the code.
The pull-based deployment strategy is the newer approach. It introduces an operator in place of the workflow. The operator monitors the repository and the environment and reconciles any differences to maintain the infrastructure as described in the environment repository. That means it will not only react to changes done to the code but also changes applied directly to the environment protecting it from drifting (at least in theory).
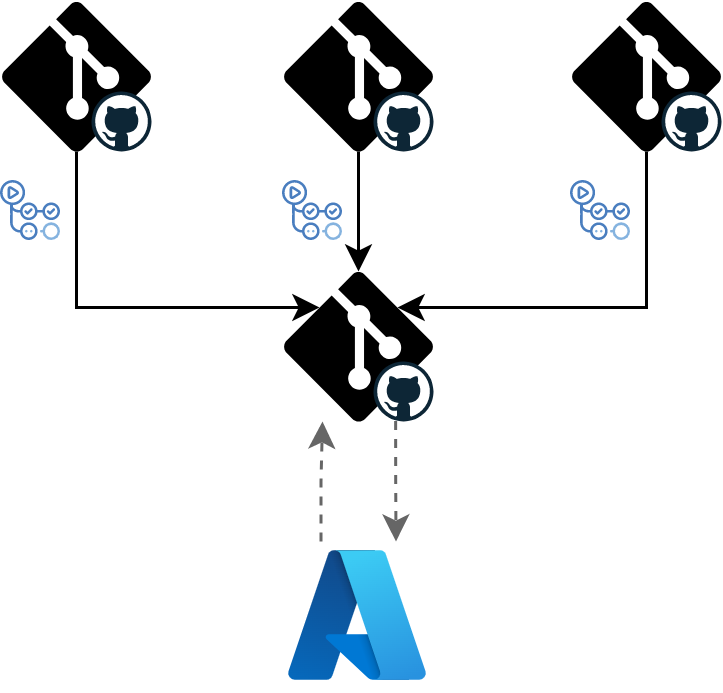
The pull-based deployment strategy has found the most adoption in the Kubernetes space with two ready-to-use operators (Flux and Argo CD). When it comes to general Azure infrastructure, the push-based strategy is still the way to go, although there is a way to have a pull-based deployment for Azure resources that are tied to applications hosted in Kubernetes. Azure Service Operator for Kubernetes provides Custom Resource Definitions for deploying Azure resources, enabling a unified experience for application teams.
In the scope of this post, I'm going to stick with a typical push-based deployment, which means checking-out the repository, connecting to Azure, and deploying infrastructure based on the Bicep file.
name: Continuous Deployment (Environment)
...
jobs:
deploy-environment:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Azure Login
uses: azure/login@v1
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Deploy Environment
uses: azure/arm-deploy@v1
with:
scope: 'subscription'
region: 'westeurope'
template: 'environment/environment.bicep'
The Journey Continues
The same as with the previous post, this one also just scratches the surface. There are many variations possible, depending on your needs. It can also by further automated - for example the Continuous Delivery implementation can be automatically creating a pull request to the environment repository. Part of the DevOps culture is continuous improvement and that also means improving the practices implementations itself.
Our journey is also not over yet, there are a couple more practices I would like to explore in the next posts, so the loop is complete.

If you want to play with the workflows, they are sitting on GitHub.